
In the vast expanse of the digital universe, web crawlers play a pivotal role in navigating and indexing the endless streams of information. These automated bots, often referred to as spiders, are the unsung heroes behind the seamless search experiences we enjoy today. But what exactly are web crawlers, and why are they so crucial in the digital age? How do we make sense of it all? Enter the unsung heroes of the web: web crawlers.
The Evolution of Web Crawlers: Web crawlers have come a long way since their inception. Initially, they were simple programs designed to fetch web pages and index their content. Over time, they have evolved into sophisticated systems capable of handling complex tasks such as parsing dynamic content, managing large-scale data, and even understanding the context of web pages.
Importance in the Digital Age: In today’s digital landscape, web crawlers are indispensable. They power search engines, enabling users to find relevant information quickly and efficiently. Beyond search engines, web crawlers are used in various applications, including data mining, SEO analysis, and content aggregation. Their ability to systematically browse the web and index content makes them a cornerstone of the internet’s infrastructure.
In this article, we’ll demystify these tireless bots, understand their purpose, and explore their impact on our online lives. So fasten your seatbelt, fellow digital adventurers, as we embark on our journey through the intricate pathways of web crawling.
What is a Web Crawler?
Imagine a diligent librarian meticulously cataloging every book in a sprawling library. Now replace the librarian with an automated program, and the library with the internet—that’s a web crawler! Also known as spiders, bots, or crawlers, these digital explorers traverse the web, systematically collecting information from websites. Their mission? To index content, update search engine databases, and facilitate efficient navigation for users like you and me.
Web crawlers operate by following hyperlinks from one webpage to another. They start at a seed URL (often provided by search engines) and branch out, visiting linked pages, indexing their content, and repeating the process recursively. Think of them as tireless ants, tirelessly foraging through the digital terrain.
A web crawler, sometimes known as a spider or spiderbot, is an automated program that systematically browses the World Wide Web. Its primary function is to index the content of websites so that they can be retrieved and displayed by search engines. But how do these digital spiders work, and what makes them so effective?
Definition and Basic Functionality
At its core, a web crawler is a bot that starts with a list of URLs to visit, known as seeds. As it visits these URLs, it identifies all the hyperlinks on the page and adds them to its list of URLs to visit, known as the crawl frontier. This process continues recursively, allowing the crawler to navigate through the web and index vast amounts of content.
Common Terminology
Understanding web crawlers involves familiarizing oneself with a few key terms:
- Crawl Frontier: The list of URLs that the crawler plans to visit.
- Parsing: The process of analyzing a web page’s content to extract useful information.
- Indexing: Storing and organizing the content fetched by the crawler for easy retrieval by search engines.
Types of Web Crawlers
Web crawlers come in various forms, each designed to serve specific purposes. From search engine crawlers to commercial and open-source crawlers, these digital tools are tailored to meet diverse needs.
Search Engine Crawlers
Search engine crawlers, such as Googlebot and Bingbot, are the most well-known type of web crawlers. Their primary function is to index the content of websites so that they can be retrieved and displayed in search engine results. These crawlers are designed to handle large-scale data and ensure that search engines provide relevant and up-to-date information.
Commercial Crawlers
Commercial crawlers are used by businesses for various purposes, including SEO analysis, content aggregation, and competitive intelligence. These crawlers are often customized to meet the specific needs of the business, allowing for targeted and efficient data collection.
Open Source Crawlers
Open-source crawlers are freely available and can be modified to suit individual needs. They provide a cost-effective solution for those looking to build their own web crawling systems. Popular open-source crawlers include Apache Nutch and Scrapy.
How Do Web Crawlers Work?
The inner workings of web crawlers are a blend of sophisticated algorithms and meticulous processes. Understanding how these digital spiders operate provides valuable insights into their role in the digital ecosystem.
The Crawling Process
The crawling process begins with a list of seed URLs. The crawler visits each URL, fetches the content, and identifies all the hyperlinks on the page. These hyperlinks are added to the crawl frontier, and the process continues recursively. The crawler uses various algorithms to prioritize which URLs to visit next, ensuring efficient and comprehensive coverage of the web.
Seed URL and Starting Point:
-
- Crawlers begin their journey at a seed URL, typically provided by search engines or other applications.
- From there, they extract links and metadata from the page.
Following Links:
-
- Crawlers follow hyperlinks to other pages.
- They prioritize high-quality, relevant content and avoid traps like infinite loops.
Indexing Mechanisms
Once the content is fetched, the crawler’s job is far from over. The next step is indexing, where the content is analyzed, organized, and stored in a way that allows for quick retrieval by search engines. This involves parsing the content, extracting relevant information, and creating an index that maps keywords to the corresponding web pages.
Indexing Content:
-
- As they visit pages, crawlers analyze text, images, and other media.
- They create an index—a massive database—of keywords, phrases, and their associated URLs.
Recursion:
-
- Crawlers repeat the process, moving from page to page.
- They discover new links, expanding their reach across the web.
Respecting Robots.txt:
-
- Crawlers adhere to the rules set in a website’s
robots.txtfile. - This file specifies which areas of the site are off-limits.
- Crawlers adhere to the rules set in a website’s
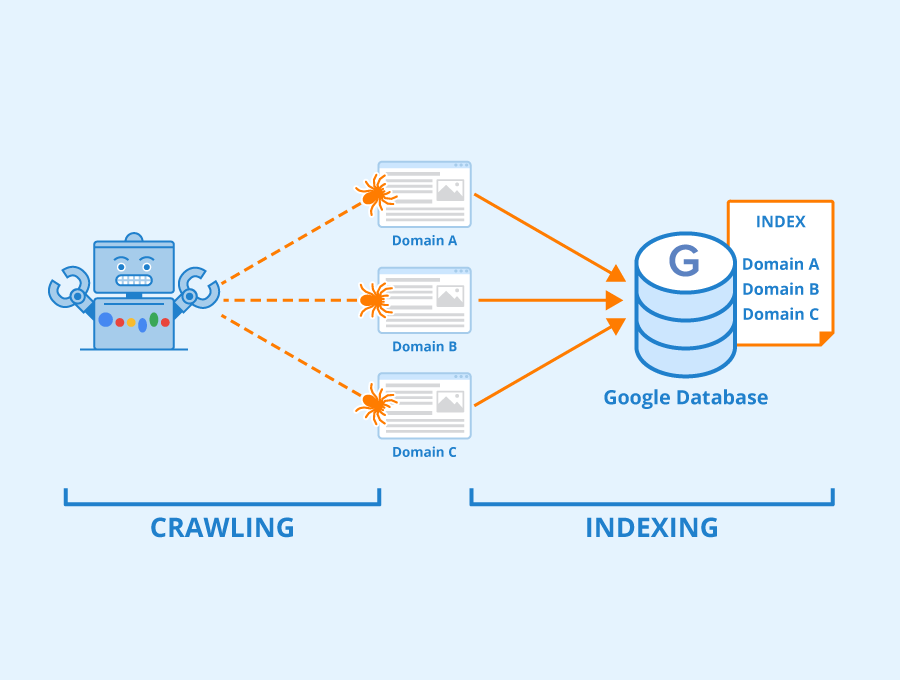
Web Crawlers and SEO
Web crawlers play a significant role in search engine optimization (SEO). Understanding their impact on search rankings and implementing best practices for optimization can significantly enhance a website’s visibility and performance.
Impact on Search Rankings
Web crawlers determine how search engines index and rank web pages. Factors such as the quality of content, the structure of the website, and the presence of relevant keywords all influence how a page is indexed and ranked. Ensuring that a website is crawler-friendly is essential for achieving high search rankings.
Best Practices for Optimization
To optimize a website for web crawlers, consider the following best practices:
- Use Descriptive URLs: Ensure that URLs are descriptive and contain relevant keywords.
- Optimize Metadata: Include relevant keywords in the title tags, meta descriptions, and header tags.
- Create Quality Content: Focus on creating high-quality, original content that provides value to users.
- Ensure Mobile-Friendliness: With the increasing use of mobile devices, ensuring that a website is mobile-friendly is crucial for SEO.
How GoogleBot Works
GoogleBot works by building a sitemap. And the database of links found to determine the next location.
Simply put, when your website has any new changes. GoogleBot will collect and add them to the list of next pages to visit. If the previous links have changed or problems will occur. Bot will automatically note and update the index list.
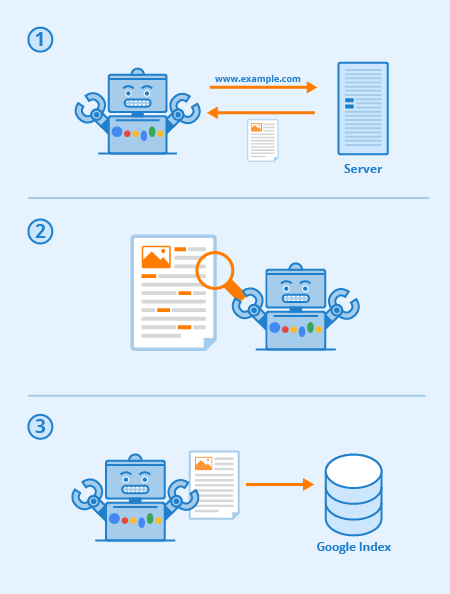
What is the Impact of Web Crawler?
GoogleBot will automatically access the website to set up the paths and you do not need to do anything. The bots will search every corner of the website. To collect all the information, the paths allow them to go through. However, in terms of SEO, you need GoogleBot to record all the changes on your website as quickly as possible. To be indexed and improve the ranking after each update.
How to block What is a web crawler? ? Think about it If your website does not allow Bots to crawl, the paths to your website are very limited. Therefore, optimizing for GoogleBot will be very beneficial for your website. Surely, your website will have a high ranking on Google. And increase visibility. Google search results.
Challenges Faced by Web Crawlers
Despite their sophistication, web crawlers face several challenges that can impact their effectiveness. Understanding these challenges is essential for optimizing web crawling processes.
Handling Dynamic Content
Dynamic content, such as JavaScript-generated pages, poses a significant challenge for web crawlers. Traditional crawlers may struggle to fetch and index such content, leading to incomplete or inaccurate indexing.
Dealing with Duplicate Content
Duplicate content can confuse web crawlers and negatively impact search rankings. Implementing strategies to manage and minimize duplicate content is essential for maintaining the integrity of the indexing process.
Ethical Considerations
Web crawling raises several ethical considerations, particularly concerning privacy and respect for website owners’ preferences.
Respecting Robots.txt
The robots.txt file is a standard used by websites to communicate with web crawlers. It specifies which parts of the website should not be crawled. Respecting the directives in the robots.txt file is essential for ethical web crawling.
Privacy Concerns
Web crawlers must navigate the delicate balance between gathering information and respecting user privacy. This involves adhering to legal regulations, such as the General Data Protection Regulation (GDPR), and ensuring that sensitive information is not inadvertently collected or misused.
Popular Web Crawlers
Several web crawlers have gained prominence due to their efficiency and widespread use. Understanding these popular crawlers provides insights into their unique features and functionalities.
Googlebot
Googlebot is the web crawler used by Google. It is renowned for its sophisticated algorithms and ability to index vast amounts of content quickly and accurately. Googlebot plays a crucial role in determining search rankings and ensuring that users receive relevant search results.
Bingbot
Bingbot is the web crawler used by Microsoft’s Bing search engine. Similar to Googlebot, Bingbot is designed to fetch and index web content efficiently. It uses advanced algorithms to analyze and rank web pages, contributing to the overall search experience on Bing.
Others
Other notable web crawlers include Yahoo Slurp, Baidu Spider, and Yandex Bot. Each of these crawlers has its unique features and serves specific regions or purposes, contributing to the diversity of web crawling technologies.

Building Your Own Web Crawler
Creating a custom web crawler can be a rewarding endeavor, offering the flexibility to tailor the crawler to specific needs and applications. Here’s a step-by-step guide to building your own web crawler.
Tools and Technologies
Several tools and technologies can aid in the development of a web crawler. Popular choices include:
- Python: A versatile programming language with libraries such as Scrapy and BeautifulSoup.
- Apache Nutch: An open-source web crawler that is highly extensible.
- Heritrix: A web crawler designed for web archiving.
Step-by-Step Guide
- Define Objectives: Determine the specific goals and requirements for your web crawler.
- Choose a Programming Language: Select a language that suits your needs, such as Python or Java.
- Set Up the Environment: Install necessary libraries and tools.
- Develop the Crawler: Write the code to fetch, parse, and store web content.
- Test and Optimize: Run the crawler on a small scale to identify and fix any issues.
- Deploy and Monitor: Launch the crawler and monitor its performance to ensure it meets your objectives.
Web Crawlers in Data Mining
Web crawlers are invaluable tools in the field of data mining, enabling the extraction of large volumes of data from the web. This data can be used for various applications, from market research to academic studies.
Applications in Big Data
In the realm of big data, web crawlers facilitate the collection of vast amounts of information that can be analyzed to uncover trends, patterns, and insights. This data is crucial for businesses looking to make data-driven decisions and gain a competitive edge.
Case Studies
Several case studies highlight the effectiveness of web crawlers in data mining. For instance, e-commerce companies use web crawlers to monitor competitor prices and adjust their pricing strategies accordingly. Similarly, researchers use web crawlers to gather data for academic studies, enabling them to analyze trends and behaviors on a large scale.
Future of Web Crawlers
The future of web crawlers is poised for exciting developments, driven by advancements in technology and evolving digital landscapes. Here are some emerging trends and predictions for the next decade.
Emerging Trends
- AI and Machine Learning: The integration of AI and machine learning into web crawlers will enhance their ability to understand and interpret web content, leading to more accurate and efficient indexing.
- Real-Time Crawling: The demand for real-time data will drive the development of web crawlers capable of fetching and indexing content instantaneously.
- Enhanced Privacy Measures: As privacy concerns grow, web crawlers will need to adopt more robust measures to protect user data and comply with regulations.
Predictions for the Next Decade
In the next decade, we can expect web crawlers to become even more sophisticated, leveraging advanced technologies to navigate the ever-expanding digital landscape. Their role in powering search engines, data mining, and various other applications will continue to grow, making them indispensable tools in the digital age.
Why is Web Crawler slow to crawl?
The speed at which Googlebot crawls a website can be slow depends on many factors. Some of the reasons why Googlebot crawls slowly are:
Slow Server
If the website loading speed (Pagespeed) is not optimized, the waiting time is too long. Reduces the chance of GoogleBot visiting the website. Not only is the access frequency of the Bot reduced. But the depth in the content collection process is also dragged. At that time, the website is difficult to achieve high rankings because SEO activities are greatly affected. Google has bad reviews for the website.
Many errors appear on your website
A website has too many errors, hindering GoogleBot’s data collection. To improve those errors, you must fix all the errors you are encountering. You can also view those errors in Google Search Console. To ensure that there are not too many errors. You need to regularly visit and check information about the website.
URLs are too dense
GoogleBot will go through all the pages on your website to build a complete site. In particular, the appearance of unnecessary URLs will prolong the time for GoogleBot to retrieve data. This is one of the reasons why information is collected slowly.
What to do to make GoogleBot visit your website regularly?
To get GoogleBot to visit your website regularly, you can see the following suggestions:
What is Web Crawler Lockout Technique?
Part of SEO is trying to keep GoogleBots on your site as long as possible. So they can access more content and create a detailed sitemap.
For content: In articles, prioritize linking to the homepage, choose the appropriate category and determine the keywords to SEO.
Categories: Build categories that are structurally separate, build articles according to the content of each category. Set the rel=nofollow attribute for categories that do not have SEO content.
Website interface (Footer, header, sidebar): Build a balanced link system on the interface. Do not place many links close together and display the same continuously between areas.
Using Google Search Console
Out of question What is Web Crawler? Many people still wonder what is Google Search Console? How to declare GSC? Search Console is a free tool from Google. Search Console can help you monitor, maintain and report website-related issues. From there, evaluate the website’s position on Google search results. This tool can provide the following actions on the website:
Find and provide data from website to Google
+ Report on indexing issues and indexing requests with new or updated content.
+ Report information about website search activities on Google.
Set up command buttons
GoogleBot will be attracted by backlink sources or natural visitors. Website administrators often prioritize building action buttons. Such as: like, share, comment to attract GoogleBot to stay on the website longer.
Even a small change on your website will be saved by Google. And directly reflected in the data search results. The clearer the information and index. The faster GoogleBot sets up, the higher the chance of improving website indexes.

Conclusion
Web crawlers are the backbone of the digital world, enabling the seamless navigation and indexing of vast amounts of web content. From powering search engines to facilitating data mining, their impact is far-reaching and indispensable. As technology continues to evolve, web crawlers will undoubtedly become even more sophisticated, driving innovation and efficiency in the digital age. Embracing these advancements and understanding the intricacies of web crawlers will be crucial for anyone looking to navigate the digital labyrinth successfully.
FAQs
What is a web crawler?
- A web crawler is an automated program that systematically browses the web to index content for search engines and other applications.
How do web crawlers impact SEO?
- Web crawlers determine how search engines index and rank web pages, making them crucial for SEO. Optimizing a website for web crawlers can significantly enhance its visibility and search rankings.
What are the ethical considerations for web crawling?
- Ethical considerations include respecting the directives in the robots.txt file, protecting user privacy, and adhering to legal regulations such as GDPR.
Can I build my own web crawler?
- Yes, building a custom web crawler is possible using tools and technologies such as Python, Scrapy, and Apache Nutch. It involves defining objectives, writing code, and testing the crawler.
What challenges do web crawlers face?
- Challenges include handling dynamic content, managing duplicate content, and navigating privacy concerns.
What is the future of web crawlers?
- The future of web crawlers will be shaped by advancements in AI, real-time crawling capabilities, and enhanced privacy measures. They will continue to play a vital role in the digital ecosystem.
How Do Web Crawlers Handle Dynamic Content?
- Crawlers execute JavaScript to access dynamically generated content.
- However, some AJAX-heavy sites may pose challenges.
Can Crawlers Access Password-Protected Pages?
- Generally, no. Crawlers respect privacy and won’t bypass login walls.
Do Crawlers Influence SEO?
- Yes! Properly optimized sites attract crawlers, leading to better search rankings.
Can I Block Crawlers from My Site?
- Yes, via the
robots.txtfile. But be cautious—it affects visibility.
Are There Bad Crawlers?
- Unfortunately, yes. Some scrape content for spam or malicious purposes.
How Often Do Crawlers Visit My Site?
- It varies. Frequent updates attract more visits.
Comment Policy: We truly value your comments and appreciate the time you take to share your thoughts and feedback with us.
Note: Comments that are identified as spam or purely promotional will be removed.
To enhance your commenting experience, consider creating a Gravatar account. By adding an avatar and using the same e-mail here, your comments will feature a unique and recognizable avatar, making it easier for other members to identify you.
Please use a valid e-mail address so you can receive notifications when your comments receive replies.